
The inference industry has trained customers to accept lock-ins as the price you pay for getting a discount. I think that's backwards.
If you've ever signed a GPU or inference commit, you know the drill. You forecast your usage 12 months out, pick a hardware SKU, lock in a model, and sign, patiently waiting for 6+ months for your hardware to be available.
Then a better model drops. Your traffic shape changes. Or you realize that you can break down the task into smaller models which require different capacity. Suddenly the hardware you reserved is now a generation behind. And you're stuck paying for capacity that you can’t rely on systems that are quickly becoming obsolete.
Committing to an inference provider should give you more flexibility, not less. You're placing bets and risking capital in one of the most volatile markets on Earth. To move at the speed the market demands, you need an inference commit that flexes with you.
Four issues I see with most dedicated inference commits
Making a commitment to dedicated inference should be a launchpad for growth. But that’s not what I see from most managed inference providers. Four commit structure problems keep showing in my recent conversations with AI founders:
1. They lock you to hardware.
You sign a 12-24 month commit to a specific GPU cluster or type. A new generation lands six months in and now you’re stuck renegotiating while your product and balance sheet suffer. The commit was supposed to give you stability. Instead it gave you a hardware bet you didn't want to make.
2. They lock you to a model.
Most commits are scoped per model deployment. Want to add a second model? New contract. Want to switch to the model that came out last week? New contract. The commercial structure fights the velocity you need to stay ahead.
3. They penalize you for not predicting capacity.
Use less capacity than expected? The unused spend evaporates at the end of the billing period. Get an unexpected usage spike? That extra capacity comes with a punitive overage rate. In this market, nobody can predict their usage 12 months out (and nor should they have to to get the best deal.)
4. They charge an idle hardware tax.
Most AI workloads have lumpy traffic that doesn’t flow 24/7. But when you’re paying by the GPU hour, the bill is the same whether the hardware is busy or not. Inference providers know this and use it to make the discounted math work for them while you’re stuck footing the usage risk.
Signing a deal like this feels less like a partnership and more like placing a massive bet on the future of your business.
Your commit structure should adapt to you, not the other way around
Four things I believe every inference commit should be structured around:
- Only pay for what you use on every request you run across your inference workload. Get a dedicated endpoints without paying for idle GPU time.
- Secure capacity without locking into hardware. Scale up, move to a new GPU generation, or reconfigure around a new model mid-contract without scrambling to renegotiate.
- Spin up any model type and run multiple models in parallel, all on the same balance.
- Negotiable SLAs and SLOs that flex as the frontier moves and the model landscape changes. The contract isn’t contingent on what you're running, only the dollars of inference you consume.
When we designed Parasail's commit, we structured around outputs, not hardware. That means you're committing to a dollar amount of inference, not a specific SKU or model.
This allows our commit structure to flex as your usage and the AI frontier evolves. Any model, any hardware, configured to your workload with the ability to switch as needs change.

Get more capacity without delays or penalty fees
Say you have a viral spike in traffic that you didn’t budget for. With Parasail when you get your quarterly invoice, you’ll see next quarter's commit + this quarter's overage billed at the same discounted rate. We don't do overage penalties.
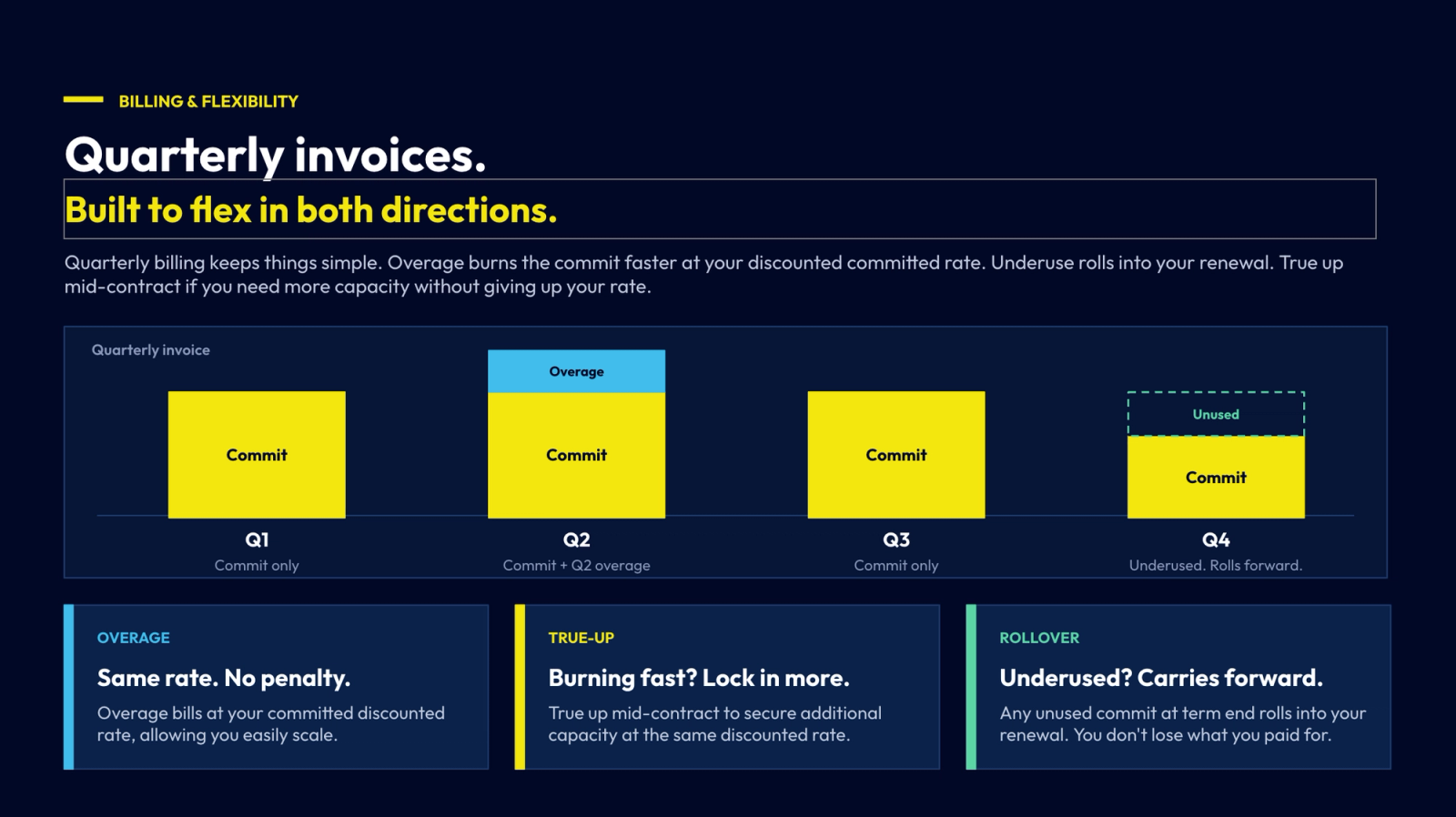
If you burn through your quarterly commit faster than expected, you won't get hit with a different price. We’ll reconcile on the next invoice at the same committed rate, no surprise charges or scramble to renegotiate. Our commercial structure should never be the reason your growth slows down.
Stay protected on the upside and the downside
You should be able to commit aggressively without needing to forecast perfectly. Our commits protect you against both overshooting and undercutting your growth predictions by allowing you to True-up and Rollover.
- True-up: Burning your commit faster than planned is usually a good problem. When your product is taking off, the last thing you should be thinking about is renegotiating your inference. With Parasail you can true-up mid-contract and secure additional capacity at your discounted rate for the rest of the term.
- Rollover. Your committed spend shouldn’t just disappear at the end of the term. Our commits transfer any unused inference into your next quarter. Since you don’t risk losing what you paid for, you can commit aggressively knowing you're protected if you overshoot.
Why we can offer this when most inference providers can't
You can't write a flexible commit on top of an inflexible operation. The reason most inference commits are rigid is because most inference providers are provisioning hardware in fixed silos. They have a certain number of servers dedicated to their public multi-tenant API, and entirely separate servers partitioned for clients paying for dedicated deployment.
Parasail breaks this mold for two reasons. First is the way we source compute and second is how we’ve engineered a solution to keep it 95% utilized.
We're exceptionally good at sourcing GPU capacity
We’ve built a GPU fleet across multiple regions, vendors, chip classes and generations to give our customers options as they scale. Three pillars that make that possible:
- Buy + rent. We have our own GPUs and rent from a wide range of providers. More options in supply creates more options for the customer.
- Multi-type, multi-gen GPUs. We work across multiple GPU types and generations. We match the right hardware to the right workload, not whatever we happen to own.
- Always adding new vendors and regions The fleet is expanding constantly, and sourcing capacity at attractive prices is core to what we do.

The depth and breadth of our GPU sourcing is the key enabler of flexible commits. An independent reserved pool of capacity lets us offer discounted token pricing, tier-switching, and the ability to spin up new models on short notice without locking in to a 12 month contract.
We route requests across a liquid layer of compute
Capacity is only valuable if it gets used. We’ve engineered an intelligent routing layer to turn our sourced hardware into a liquid layer of compute.

We run two fluid pools of inference traffic:
- Dedicated tokens are for workloads on reserved capacity, negotiated SLAs, and predictable discounted pricing.
- Shared tokens are shared workloads we actively manage ourselves and through distribution partners like OpenRouter. That includes large-scale batch processing, serverless endpoints, and bulk capacity for coding-agent companies, foundation-model companies.
Token traffic is fungible. We can dynamically route our GPUs between our dedicated and shared pools to achieve 95% utilization of the entire fleet and provide burst capacity for our dedicated commits.
When dedicated inference demand spikes, we pull our own GPUs off shared workloads to quickly meet demand. Because we can fulfill shared workloads through distribution partners, we can do this without impacting our serverless customers.
Flexibility isn't a marketing claim, it's how Parasail is structured
Inference is moving too fast for providers to lock you into what's working right now. Your traffic shape will change. New models will drop. Better tiers will emerge. The model and hardware you commit to today almost certainly isn't what you’ll want to run in six months to a year.
Inference commits should be a platform for growth, not a bottleneck every time the frontier moves.
We built Parasail to be that growth platform for AI companies scaling inference. If you feel like your inference commit structure is working against you, reach out.